The Overview Effect is a cognitive shift that is reported by astronauts when they see the earth from outer space for the first time. It is a change brought on by experiencing the world differently. Strongly held beliefs unfold. A new mental state is acquired from seeing the whole, after a life spent living in the parts.
Fortunately for us, the effect can be had without directly experiencing outer space. The “blue marble” photograph is considered a turning point in humankind’s collective understanding of our place on earth. The picture gives us all the ability to make contact with that global view of the world.
The Overview Effect is a powerful force in generating understanding about systems, one that we can use with all systems that we interact with.
Software delivery is all about the creation of systems – technical systems, organizational systems, systems of work – and we have many opportunities to play with and utilize this effect. I try to use it as much as possible, and I think an important part of my job is to create experiences that help give people a broader view of what they are building.
Here are few examples of different overviews I have used in the design of our newest product:
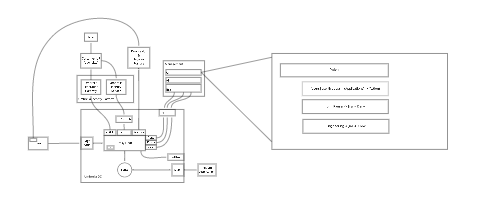
User Story Maps
Architecture Diagrams
Mind Maps
User Journeys
Even my personal Kanban
These are all ways of generating system-level views that help to couch our day to day work in a global level of thinking. They also make such views accessible to a wide audience. I consider the experience of creating and discussing these artifacts with a diverse group of people to be an invaluable part of our development process.
When we are working on large scale software projects that involve dozens of teams and hundreds of engineers, these views are not just ‘nice to have’. We need to do everything we can to help people understand what they are building. I feel that we have a responsibility to experiment with as many such views as possible, and share them as broadly as we can.
The key is to make visualexplanations (channeling my Tufte here) that pull many parts of the system together. But there is an important corresponding attitude that needs to accompany this.
The Inductive Attitude
In Mathematics and Plausible Reasoning, Polya writes,
“In our personal life, we often cling to illusions. That is, we do not dare to examine certain beliefs which could easily be contradicted by experience, because we are afraid of upsetting our emotional balance. There may be circumstances in which it is not unwise to cling to illusions, but in science we need a very different attitude, the inductive attitude. This attitude aims at adapting our beliefs to our experience as efficiently as possible.”
Polya (1954) p. 7
In science (and, yes, product development) experiences need to shape our thinking. The inductive attitude means being able to change our beliefs quickly and easily based on what we observe.
Applying the attitude to our work means we make the best possible use of available experiences: using techniques to extract diverse views of a problem and synthesizing the evidence to create new understandings. Rinse and repeat.
With the Overview Effect, we will be given a global view that may very well contradict what we previously understood only locally. As always, we need to use open minded thinking, expecting to have our mind changed when we experience this new perspective.
We may have thought we should do things a certain way that doesn’t make sense any more given the full view. We may have had our heart set on an implementation that completely missed a key element of the system.
We should be delighted to find out we are wrong, to gain new clarity on our goals.
Overall, the inductive attitude – changing our minds based on new evidence and new experiences – is critical in product development, and we see this in the fact that so much of modern product delivery systems is targeted at learning and changing our minds as efficiently as possible.
If we are going to use nudges like the Overview Effect to help us build our understanding, then we must adopt and use the inductive attitude, ready to change our beliefs.
Have you had an Overview Effect that changed your thinking about how a system works? I would love to see it! Please reach out to me on Twitter if you have.
In the late 1800s George Cantor stunned the world by proving the existence of the unknown: he showed that there are uncountable numbers and even sets of numbers.
His work laid the foundation for a wide range of paradoxes that lie at the edge of human knowledge, like Godels incompleteness theorems, Russel’s paradox, and the halting problem. For mathematicians, it was the start of over a hundred years of work that continues to this day. For you and me, it serves as a reminder that there is more to the world than we take for granted.
At the heart of Cantor’s work is the “diagonal proof”, which is simple, elegant and surprisingly easy to understand. I’ll just brush up the Wikipedia article a bit and let it do the explaining:
The proof starts with a family of sets, for example these sequences of binary numbers:
Next, a new sequence s is constructed by choosing the 1st digit as complementary to the 1st digit of s1 (swapping 0s for 1s and vice versa), the 2nd digit as complementary to the 2nd digit of s2, and so on. For every n, the nth digit is made complementary to the nth digit of the set before it. This yields:
By construction, the new set s differs from every other sn, since their nth digits differ (highlighted above on the diagonal). Hence, set s cannot occur in the enumeration.
So by moving diagonally through the sets, we have generated a new set that isn’t in the original. And now when we add it to the original, we will usher into existence another new constructive set that did not exist! This will go on and on forever. In other words, the set sn is uncountable.
Think Diagonally
The diagonal proof is a simple way of revealing the existence of something underneath the obvious. It is a reminder for us that the answers we are looking for are not always forthcoming, and that we may be asking the wrong questions.
As we go about our daily lives building software products and delivering value to customers, we need to think diagonally. A famous quote by Steve Jobs illuminates this sentiment well with an apocryphal quote from Henry Ford:
“Some people say, “Give the customers what they want.” But that’s not my approach. Our job is to figure out what they’re going to want before they do. I think Henry Ford once said, “If I’d asked customers what they wanted, they would have told me, ‘A faster horse!'” People don’t know what they want until you show it to them.”
Steve Jobs
This captures that idea of “something out there” that hasn’t been found yet, and won’t be found by merely counting what already exists. And this awakening to the unknown is a key part of diagonal thinking.
But there is another part that is captured well by a quote from Henry Ford, this time a real one:
“If there is any one secret of success, it lies in the ability to get the other person’s point of view and see things from that person’s angle as well as your own.”
Henry Ford
This captures the idea that it is worth taking the time to look at those unrevealed sets. By moving diagonally through perspectives, we can generate new ones that don’t exist yet. Steve Jobs may disagree, but there is value in doing this for many different reasons, e.g. to develop empathy and to create diversity.
In both cases, diagonal thinking means we do not merely accept our own point of view. We use our creative energy to build a vision and look beyond: to find the questions no one knew to ask, to uncover a new answers previously unseen, to go after the unanswerable.
“Trying to find the solution, we may repeatedly change our point of view, our way of looking at the problem. We have to shift our position again and again.”
How To Solve It, Polya
Whether you are trying to figure out what customers want, or trying to figure out innovative ways to build it, it helps to remember that there is always another perspective on your problem waiting to be uncovered, and possibilities that remain undiscovered.
Are you counting what’s already there? or are you looking for the uncountable?
Think diagonally.
A visual representation of algebraic numbers on the complex plane coloured by polynomial degree. Points become smaller as the integer polynomial coefficients become larger. (source)
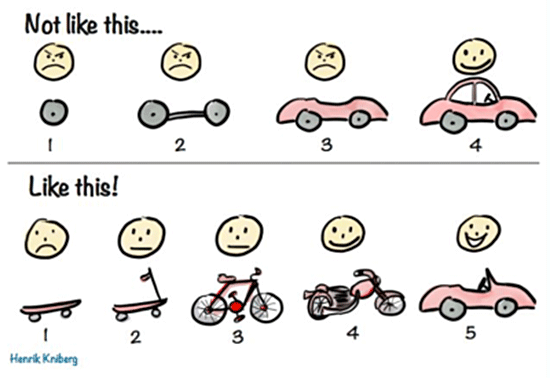
Software development is driven by learning experiences that generate knowledge
Knowledge is contextual to one’s perspective
Perspective is impacted by the relativity of information
Relativity means observations are inconsistent across locations
To build great software, we need to account for relativity in our systems of work
An important part of software development is that it is driven by experiences—we learn about our systems through hands-on work—spiking and prototyping, experimenting and testing.
We try to have rich experiences using a variety of tools, practices, events, and concepts. We use those experiences to generate ideas and data, confirm or deny assumptions, and solve problems.
This is our process of creation: write something, build something, see if it works, evaluate. The code we write, the way we write it, the tests we use, the packages we import, the systems that we deploy it onto—we are going to bring all these all together through our creativity, using experiments to learn our way into an overall structure and architecture.
So we cut some cards on the Kanban, get a few people together, pull some work. Soon enough we have something, we demo it to ourselves, we demo it to a customer, and then hey-whaddya-know! someone is actually getting value from our creation.
Now I ask you—at what point did the software exist?
When did we move from nothing to something?
—
We all come to the table with a different view of the world. We all understand what it means to “exist” differently. For one person it’s when the wireframes are built. For another, it’s not until the first tests are passing. And for the finance team? Way back when the budget got approved. You get the idea.
We can call this “perspective”—things have different meaning depending on where you observe them from.
It is interesting to think that something as fundamental as ‘existence’ can differ depending on what “hat” you are wearing. Compared to objects in the real world, this is an awkward thing to wrap your head around. The furniture in my house exists whether I’m an engineering manager working from my living room or a traveling salesman trying to find the shortest path between cities.
But for “processes,” this is actually quite normal (which is what we have been describing so far —a process). They are abstract n-dimensional graphs, materially different depending on who is examining them, and in ways that one might not expect if one is not used to working with abstractions.
This sounds cool, but it is not novel, because it is true about other processes in business. If I am building a skyscraper, I work with many different disciplines to do the construction, and all of them will look at different criteria to assess their overall state of existence. (Though, again, this is much less obvious because the focus of the work is on real objects and not abstractions).
Where perspective gets really interesting is when you bring in the concept of relativity.
Relativity
Relativity was introduced to the world at the beginning of the last century when Einstein proved that reality is fundamentally different depending on your frame of reference. A distortion of the spacetime continuum occurs that is only noticeable at very large and very small scales. The concept has led to the discovery of black holes, gravitational lenses, time dilation, and all kinds of other fantastic things.
Relativity is not at all what one would expect based on our regular day-to-day lives that operate according to classic laws of physics. It changes what it means to observe and to be an observer—it means that how we experience the world differs not just in how we interpret it. There are circumstances where the world I experience is inconsistent with yours.
It turns out that communication has these same characteristics and works in this same peculiar way. Information is distorted depending on the location of the observer.
Mark Burgess calls this “information relativity”: messages can take multiple paths and interfere with one another, information can be reversed in its order as it travels along one path, the speed of communication can be different from the speed of communication on another path.
All this extends the problem of communication beyond the classic problems of how meaning differs, and into issues of consistency.
We are well aware of consistency issues in building distributed systems. We have the CAP theorem to describe some of the trade-offs we need to make against availability and partitioning. We have the idea of eventual consistency, which is now a household word (in my house). This is a tremendous problem to solve on a day-to-day basis in the dynamics of a distributed system, but it also plays an important role in our organizational dynamics, too.
Unlike building a skyscraper, in a software system, we are only ever working with representations, never “real things.” Our ability to obtain representations depends on the fidelity of our information networks—systems of people, tools, processes, and artifacts. The impact of information relativity on their dynamics is a key impediment to value that we all need to think about when we are building systems.
Take the problem of calculating capacity for a service across a multitude of microservice owners. Perhaps they are working together to build a capacity plan for customer forecasts. Depending on which information sources they access, the way they access them, the queries they run, and even the time of day they run them, each group is liable to arrive at different results. This is true whether we are talking about the infrastructure or the sales data. Arriving at a consistent representation of capacity becomes difficult and time consuming.
Or take the problem of managing an incident, where multiple teams need to work together to determine what is failing and how to fix it, then return later to understand why it failed and what can be done to improve the system. Depending on what team you sit on, you will use different tools to look at a phenomenon on different scales. We observe traces of the same phenomena in different ways, arriving at different understandings and perspectives on causality. Incident analysis is made difficult if we don’t take action to mitigate the relativity problems.
These are difficult problems, and we have not even started talking about the classic issues of whether we understand our measurements to mean the same thing or whether we are measuring the same things in the same way.
So to build great software, we start with those classic problems of perspective, but we also need to grapple with questions of relativity, which does not operate according to the classic deterministic principles that we all know and love, the principles that operate when you eat a sandwich or bike to work.
We depend on unreliable materials—stories and data that build mental models about what is happening, and which are only ever in a partially-correct, never-stable state.
Though our systems are based on 1s and 0s, the answers to our questions are not true or false. Quite the opposite, our knowledge exists somewhere on a spectrum of strong and weak inferences.
And this is the heart of our synthetic systems. We need to design systems of work that take into account the relativistic nature of our knowledge.
To be successful we need to think in terms of probability, not determinism. The unsuccessful will assume that what they hear (and think, and see) has been determined by the past or determines something in the future. But in our world of information dynamics, determinism is a harmful paradigm to try to work inside.
When designing our systems, we need to take into account this challenge to our ability to learn and generate knowledge using practices that,
Assume variability: the impact of relativity is difficult to predict, so we need to focus on strategies that emphasize eventual convergence rather than trying to get things right upfront.
Use systems thinking: we won’t factor in relativity when we are only thinking about a subset of the system, or ignoring human factors.
Provide fast feedback: we cannot detect and respond to problems of inconsistency if we are not getting feedback on our decisions.
It is interesting to consider that many practices that are emerging from software, like Agile and DevOps, are implicitly designed to deal handle these challenges. They allow us to correct the drift in our mental models and understanding.
But this thinking is not self-evident. The same way Einstein discovered that the world works differently underneath the atom, we are still discovering the way things work differently in the world of information. What are the black holes and gravitational lenses in the physics of synthetic systems? What is still waiting to be discovered in the world of software development? History says, a lot more.
Skin in the game means decision-makers bear the consequences of their decisions, both the risks and the rewards.
All systems need this attribute to drive evolutionary pressure
Software development has suffered greatly from a long history of trying to separate consequences from decisions in the name of efficiency
Modern software practices and management systems have reversed the trend and put skin back in the game
In his famous lectures on physics, Richard Feynman explains that the test of all knowledge in science is the experiment. This is the sole source of scientific truth. But where does the knowledge to experiment on come from? In physics, the thinking process is so difficult that there is a division of labor – theoretical physicists dream up new ideas, and experimental physicists design the experiments to test them.
This division of labor between ‘thinking’ and ‘doing’ might make sense if you are trying to understand the origins of the universe, but here on earth – in the real world – we do not have the luxury of letting others dream up experiments for our own lives. Consequential decisions need to be made by those who pay for the consequences, by the people with skin in the game.
Skin in the game drives evolutionary pressures across a system by ensuring decisions come with both the rewards and the risks. When bad decisions are made in a system designed with skin in the game, selection processes will either alter the decision or eliminate the decision-makers. Remove skin in the game, and evolutionary pressure goes with it – bad decisions can be made without consequences.
In software, where our work is made up entirely of systems building, we have continuously missed this crucial point, lining up countless teams in front of the firing squad of asymmetry.
Throughout the history of software, managers have tried to design methods of engineering that pull everything they can away from the teams writing code. Theoretically this should make things faster: “With the division of labor we can create a software factory!” But in reality, this creates a system with artificial incentives (e.g. lines of code, test coverage) that have nothing to do with the value being delivered to customers.
There has been a compulsion to think of only “the software” as a “the system”, and that once decisions (in the form of code) are put into the system, they take on a life of their own and can exist independently of the decision-makers.
But software systems are sociotechnical and our decisions do not detach from the decision-makers, only the consequences do. The fitness of the system needs a connection to consequences. This is what we have been struggling to figure out in our methodology for building software.
Systems of Software Engineering
Software is made through the accumulation of a great many small decisions from different people over a period of time. We write those decisions into code, but they are based on imperfect information and need to be updated as we learn. If learning feedback loops are in place then the good decisions will stick around, the bad ones will get replaced, and the system will evolve.
The learning comes from all over, not just from writing code but also from designing, planning, testing, monitoring, securing, operating, maintaining, demonstrating, using the system.
The great folly of software engineering is to think you can anticipate what will be learned in those other activities without having to participate in them, because that is where the risk of our decisions is uncovered, sometimes quite dramatically.
Systems of engineering that move those activities away from developers remove the connection to the risk they are creating, which destroys evolutionary pressure and generates software systems that are fragile, expensive, and difficult to maintain.
We learned many hard lessons, and they run up and down the development stack. To name a few obvious ones:
It’s why we do DevOps. “You build it, you run it” – Werner Vogels, CTO of Amazon, saw this clearly: if you don’t run the code you write, you have no skin in the game. When one group does the building and another group does the running, you get the pernicious separation of thinking and doing, the division of decision-making and risk-bearing.
It’s why we killed QA teams. When one team is writing code and the other team is figuring out how to test it, you remove the direct contact between how it works and how it fails. Outsourcing all the “testing” does the exact opposite of what is intended: it creates bad software by removing the evolutionary pressure needed to stop bad code from entering the system.
It’s why we build products, not projects. Projects have one group doing the planning, and another group doing the work. But it’s easy to set a date when you don’t have to figure out how to meet it. Ironically, separating the planning from the “doing” removes predictability from the system. Developers end up burning out or shipping bad systems to meet deadlines dreamed with no skin in the game.
And we are still learning many hard lessons
Why is security still so poor in software? Because it’s mostly compliance frameworks created by checklist mafia with zero skin in the game. Cringe hard when you hear about how security is now a C-level problem. What a terrible place to put the problem, in the hands furthest away from the people doing the doing.
But overall the industry trend is to create systems of engineering that put skin back in the game. Over the past two decades, synthetic management systems and technical practices have emerged that do just that. Full-stack teams that start together with collective ownership of outcomes. Practices like Agile, DevOps, Continuous Integration and Continuous Delivery work together to remove encumbrances on the ability to own the risks that we create with our systems.
The important question to ask is, how can we maximize skin in the game? How can we give developers the most direct contact with the risks they create? There is one practice that provides such contact, having a privileged position that creates a unique form of skin in the game that is unparalleled in the business world.
The Practice of On-call Engineering
Going “on-call” means that on some regularly-occurring cadence, you put down your regular work and spend a week working directly on the system. This means two things:
Carrying a pager, responding to issues in real time as they happen, and pulling in others if something serious is happening.
Doing the work needed to maintain the system, tuning monitors and alerts, working on regularly occurring tasks, or making small improvements to optimize the on-call experience.
For a system where developers go on-call, the connection to risk they create could not be greater. If monitors are generating a lot of unreasonable or unactionable alerts, if components are loaded up with manual tasks and un-automatable issues, if the system is complicated and difficult to debug, it is the people who created those problems that must suffer.
On-call engineering creates skin in the game in a way that deeply shapes our understanding of the world.
“What matters isn’t what a person has or doesn’t have; it is what he or she is afraid of losing.”
An incomplete list of things that one loses when one goes on-call for a hard-to-operate system (in no particular order): sleep, weekends, evenings, time working on things the enjoy, general well-being. To an on-call team, the idea of putting these things at risk is morally repugnant.
And so, on-call engineering unites creates a powerful set of engineering ethics, a moral code of conduct that stems from overcoming adversity and the constant threat of ruin. Taking on risk wantonly or haphazardly is deeply offensive, in a way can be hard to understand by people who have not gone on call before.
Get Your Hands Dirty
There are different attempts to create skin in the game, but by far the most valuable asset is learning through experience. Time spent in the hot seat.
Until you have actually experienced the impact of going on-call for a software system, it is hard to imagine just how deeply it impacts your decision-making. Skin in the game therefore implies that we need people to come down from our ivory towers and experience the world:
“The knowledge we get by tinkering, via trial and error, experience, and the workings of time, in other words, contact with the earth, is vastly superior to that obtained through reasoning.”
If you want to make decisions about a product’s design or technology or architecture or technical debt or timelines or backlog or security, then join that team. If you can’t, you can offer your opinion, but you don’t get a vote. Think Pigs and Chickens, an excellent fable that was unfortunately removed from the Scrum guide 10 year ago, with nothing to replace the critical lesson it provides.
For software developers that want to build great systems, owning risk is an inescapable moral obligation. They implicitly know that most powerful force in systems-building is the evolutionary pressure brought by a direct connection to consequences. When we acknowledge this, we can use that force to drive the evolution of our systems and generate the kind of value that customers pay for, and engineers love.
Notes:
- This article was originally published in InfoQ
- The art featured in this post is "The Battle of Britain" by Paul Nash, depicting a dog fight in 1941. Fighter pilots have the ultimate skin in the game.
I picked up The Psychology of Money because it’s light, had pretty good reviews and looked like a quick read. All of these promises came true, but I didn’t expect to apply the lessons to software!
The book mainly revolves around two things that are hard to integrate into our every day thinking – 1) compounding and 2) tails.
The first comes down to this: all growth is driven by compounding, which always takes time. The impatient among us will never succeed at the long game of growth, only at the short game of gambling. And it’s not worth gambling. Why? That’s the second part.
The second pertains to risk and ruin (and from which the author borrows heavily from Nicholas Taleb. In other words, it’s a good book ;). The essence is that all long games are subject to tail events – rare, catastrophic events that mean ruin for the unprepared – and they will happen. Unfortunately we often have a very bad idea of where we actually sit inside probabilities (or we just ignore them).
What does this have to do with software?
Firstly, we are all looking for growth. Whether it is in the products we are building, or in our careers, networks, knowledge, etc. The principle of compounding applies here:
In the two-second lean tasks you do to make your product better. It pays to take the time to make improvements, remove that technical debt, document those decisions, refactor your old code. You won’t get much today, but the benefits compound over time as you and your team make a habit of small improvements.
In the daily tasks you do to learn and grow. Everyone is going to agree that it’s easier to spend an hour on Netflix than it is to take the time to learn a new thing, but an hour spent is an hour gone for ever. The dividends paid on an hour learned are huge in the long game. You are presented with this decision every single day. It’s yours and yours alone to make.
In the conversations you have with your teammates, your peers, your manager, your manager’s manager, your industry contacts and so on. You need to make an investment in these. Again the pay off might not happen today (in fact it may be somewhat uncomfortable today, since you have to figure out what to talk about!). But you should see these as long term investments that will be worth it when you run into problems down the road. Speaking of which:
Secondly, on ruin. There are all kinds of disasters that we need to protect ourselves from in software: late integrations, big bangs, building the wrong thing, outages. But there are also a variety of different practices that we can use to buy insurance: thin slicing, writing tests, incremental development, monitor driven development, and so on. When you look at these practices as insurance against ruin, and you understand a bit about probability and risk, it’s easy to make the right decision to use them.
The psychology of “money” is not really about money at all. It’s about taking a realistic approach to the way things actually work in life. And so it takes a lot of the mystery out of why things work the way they do, and the lessons can be applied to a lot of areas of life. These are lessons that pass the test of time, and that we can use in our every day decisions.
Tokyo train systems are legendary for running on time. How do they do it? A key element is pointing and calling – when taking an action, the operator points and calls it out so that everyone knows what is happening.
It may seem like drawing attention to simple things that are already obvious, but that’s exactly the point – simple things can cause really big problems when they fail. In a world where everyone cannot see everything, pointing and calling can provide a shared set of eyes.
The idea is to get in the habit of making sure that the obvious is actually obvious … by starting with simple things. It takes 1 second, it doesn’t hurt anyone, but it can world of difference.
And it’s an important lesson for us in software.
We often have to make decisions that range from very simple to very complicated. And since our work is cognitive, it’s easy for the “obvious” to get lost. What you think is obvious to others easily turns out to be not at all.
It pays to remember that it’s worth over-communicating in cognitive work such as software delivery. Similar to the “I intend to … “ practice from Turn The Ship Around, we need to be sure we are being clear about what we are doing, drawing attention to our actions so we can get feedback from others. This is a key element of being responsible with our autonomy.
Software teams already practice versions of pointing and calling. For example, we use ceremonies to draw attention to what we are doing, and in those ceremonies we use various practices to make our work visible. This is how we have learned to cope in a world where we can’t see anything (because it’s all in our heads).
And it can be as simple as saying “I’m moving this card to done” as you are transitioning a card in standup, then a second of silence to give someone the opportunity to jump in, “Well, actually ..”
Sometimes this practice is not easy to do, though:
Sometimes we point and call, but don’t actually execute. When this happens, people will have unmet expectations.
Sometimes we execute, but forget to point and call. Now we have lost the opportunity to get help, to make sure that we actually made the right decision.
We should approach such situations blamelessly. We are allowed to get these things wrong as we collectively learn a new skill. It is better to have tried and failed than not to have tried at all. Most of our decisions (or indecisions) can be reversed. Unlike in the train system:
When we spend time focussing on specific problems, it comes at the cost of the ability to focus on others. The mind becomes conditioned to make certain things invisible, no matter how many times we look them over.
In the case of this article, it might be a spelling mistake, but in the case of a product it can be all kinds of things – bugs, designs, even market fit.
But we can learn to see again. There are ways to escape the myopia, and one is the power of liminal thinking.
Rites of Passage
Transitions are an important part of human society. The “rite of passage” shows up in many forms across many different cultures, as people move from one stage of life into the next. They signify a change of status, and are said to have three phases:
Pre-liminality, a “breaking away” from the past. The metaphorical death of the previous status.
Liminality, where the subject is dislocated and temporarily lives outside the normal environment. Fundamental questions about knowledge and existence are brought to the foreground.
Post-liminality, where the subject is re-incorporated into the environment with a new status.
In the liminal period, we enter a state where we are leaving something behind, but not yet fully in something else. We are able to look outside of the context of our normal day to day experience, entering a period of scrutiny where we re-examine our reality.
After years building and releasing software products, I am noticing how liminality plays out in the process of delivering our software. It’s a useful mental model that can help us improve our systems and experiences.
The Event
Our systems enter into liminal periods through events.
Scrum is designed to continuously evoke transitional thinking through the use of various events – sprints, retrospective, refinements. During these events, we use liminality to remember tasks forgotten, find the issues left languishing at the backlog bottom, see the mistakes that should have jumped off the page.
There are also larger events as a product passes through lifecycle phases, like the beginning of early field trials, or a large public launch. As we approach these events we bring in the managers, pull out the checklists, and probably have an assortment of walkthroughs, reviews and check-ins.
Those product lifecycle transitions are great opportunities to take advantage of liminality. We can do much more than just reserve a time to review a specific set of work – testing, monitoring, security, etc.
The Liminal Space
What leadership needs to focus on is creating a liminal space for teams to inhabit.
We can use structure and semiotics to amplify the state of mind. For example, we can use bookend meetings to signal that we are entering and exiting the liminal space.
That way, when we go through the process of reviewing things, we will do more than just check boxes: we will question the intention and existence of those check boxes. We will find new ways to extend their intention and existence into our continuous processes.
Note that we may even feel a sense of guilt or shame as we engage in this process. “How could we have overlooked this? How could we have not noticed that? How did we collectively forget to do something so important?”
Fear not! Foregrounding the invisible is the goal. Software is synthetic, so we should never expect to know everything, and always be ready to uncover the unknown and unexpected.
Be careful not to punish yourself or others for what you may find, as it will set back the entire process. Proceed into the liminal period without judgment. Create a safe, blame-free space to reflect. And give yourself some credit – it takes courage to go boldly into the liminal space.
Liminal Thinking
The anthropological study of liminality tells us that it is a special and privileged time. If we recognize that we can use harness the energy to do more than just scrutinize the work: we can also revisit the central values and axioms that guided its creation.
That is what we should strive to do in this period: inspire liminal thinking. At the heart of the process is questioning the very existence of the feature itself. “Someone remind me, why did we build this?” This is a time of renewal, refresh and rebirth.
So my suggestion is this: use this time to get creative and imaginative.
Don’t ignore the opportunity for liminal thinking. Don’t just go through the motions and check the boxes. Do the reviews and the retrospectives and the rethinking, knowing you have the capability to see your system in a different way in this time.
Discover what you have unconsciously learned to unsee, question everything, and feed this back into your product and your experiences.
Building software products means coping with complexity. Our products are highly interconnected systems of systems. Dynamics are difficult to model; outcomes can be difficult to predict.
Ivory towers crumble on this unstable ground. It is not sufficient to have one person deciding for the whole group, everyone following the direction of a “grand strategist”. Decision-making in complex environments needs to be decentralized.
If we are all to take part in decision-making, then we all need to constantly improve our knowledge of the problems we face – we need to be active participants in a learning organization.
Learning is both an individual and a group experience. Organizations that excel tap the commitment to learn from people at all levels. And learning is something deeper than just taking in information. It is about changing ourselves – growing in meaningful ways that contribute to the whole. So we want to build an organizational culture that promotes a deep connection to collective growth.
I have found the five disciplines of learning from the book The Fifth Discipline helps to inspire ideas about how to develop this culture. A quick summary:
Systems thinking – seeing how all of our work connects, sharing the big picture. Proactively developing a collective understanding that we can use at all levels to spot patterns and persistent forms. Overcoming when systems develop built-in limitations to growth. (Remember, systems can be technical, organizational, managerial, etc.)
Personal Mastery – developing our ability to see our reality more clearly. Our work is creative work, and creativity results from the movement of ideas. “Still water becomes stagnant.”
Mental Models – guiding our ability to make decisions. How are we building them? Sharing them? Reinforcing them? They have a natural entropy and tendency to diverge, so they must be actively maintained and continuously refreshed.
Shared Vision – having a shared vision enables co-creation. When we have that vision present in our day to day work, we are building things together for a common goal. This helps frame the context of the learning we engage in.
Team Learning – this involves two practices: discourse and discussion. Discourse is the practice of presenting knowledge to others. Discussion is the practice of inquiry and exploration into the discourse. Both are crucial.
To build a learning org, we can start by asking the questions in these disciplines to enrich our learning experience. Questions like: How can we help other teams expand their understanding of how our work connects with theirs? How can we share our mental models with others? What activities can we do to reinforce our shared values? What kinds of “discourse” activities can we use to promote discussions?
We can start doing that today. Start by creating the Tiny Habits needed to ask these questions at the right times. We should not expect anyone to build out learning organization for us – we all need to take ownership and do our part. What are you doing to help?
It features in my favourite book by Edward Tufte, “Beautiful Evidence”, as the focal piece for explaining the principles of data presentation. It is a landmark in the history of the ‘infographic’, renowned for its cleverness (in stark contrast to the military disaster it describes).
With not much more than a glance, we can learn a great deal. We immediately see the French Army was decimated – that the approach cost many lives, that the attack on Moscow was ruinous. We see that the timing for the return to France could not have been worse, the sinking mercury being the death of many. We note that river crossings were particularly dangerous, each costing a great many thousand lives.
But something is missing.
We are missing why? Why was Napoleon attacking Russia? Why was he doing this just before the onset of Winter? And why did all these people agree to such a poorly thought-out plan?
From Minard’s analysis we know “what” happened, but we do not understand the “why” behind any of it.
In software, we spend a lot of time working in the analytic “thinking space”, a place where we are taking things apart and trying to figure out how they work. It’s a safe space, because if you do it well, you will probably be able to figure out most of what is happening. But does this help you understand why it is happening? Does this help you tell the story of your software?
What story are you telling?
To paraphrase the great Ackoff, a systematic analysis of the parts generates knowledge, but it does not generate understanding. It does not explain why things are the way they are. To create understanding we need to look not at the parts, but rather what they are a part of.
We call this the “synthetic” thinking space, a concept that is ages-old, but which gained popularity with mid-century business thinkers like Ackoff, Deming and Drucker. When we work using synthetic thinking we want to play with the pieces, we put them together and look at them in their context, we come up with ideas by experimenting and observing their interactions.
What do I mean? Let’s look at an example:
(source – me … pre-covid)
This is a user story mapping exercise. We are playing with the pieces of a story that we deconstructed earlier. This exercise is designed to evoke synthetic thinking using a diverse group of specialists (plus a lot of La Croix and Red Bull). It is part of a repertoire of activities that enable us to come up with new understandings: new reasons why.
Why do customers want us to solve their problems? Why do they want to use our software? Why are they willing to pay us money for it?
To answer these questions we experiment, we try things out, see what works, and fail constantly until we get it right. We use processes that are designed to help us put pieces together, and in ways that reveal the unique, the unexpected, and the innovative. We use synthetic thinking.
How are you telling your story?
It is not just a coincidence that we use the concept of a “story” to capture our work in software. Since the beginning of human history, stories have been used to connect the dots, to bring people together, to generate knowledge and understanding about the world around us.
Stories connect the analytic with the synthetic: Analytic thinking deconstructs the problem, creating knowledge; Synthetic thinking puts the problem back together again, creating understanding. It’s through cycles of analysis and synthesis that we can change the world.
For all forms of work, we need to ask ourselves: where should we spend the most time in these cycles?
What should we do more of or less of to drive these cycles? What story are you trying to tell?
If it’s a software story, you should be spending much of your time in the synthetic space, and using practices that support it.
That’s because software is synthetic, and for software development we have been learning to prioritize this way of thinking. It is the reason why certain practices succeed in our work. It is the unstated undercurrent that runs beneath many of our successful practices: synthetic work requires synthetic management.
What color do you think of when you hear the word “red”?
Ask 100 people, they will give you 100 different answers. Even with an anchor to help—a can of Coke, perhaps—there will be differences.
So begins The Interaction of Color by Josef Albers, where he uses various color studies to show the complexity of their interactions. He notes that even professional artists are surprised when presented with his examples, which indicates just how fickle the human mind is at interpreting color.
To train the eye, he has learners run experiments that demonstrate concepts like intensity, brightness, reversal, transparency, addition, subtraction, mixture, and so on. In doing these experiments, students work through various scenarios, manipulating color combinations to reveal their interactions.
It is interesting to note that Albers does not use pigment or paint for such experiments. Instead, he uses paper cut-outs. These provide the most reliable way to test scenarios repeatedly. The printed colors are fixed and indivisible.
Indivisible elements are critical for experimentation because they are irreducible. They create a high degree of reliability, which is needed to work with tests and compare results.
In software, we also engage heavily in experiments, and we also need indivisibles to work with. We call these “primitives,” and they come in two types—dynamic and semantic.
Primitives of Dynamics
Software is built from layer upon layer of abstractions. Machine language is abstracted using microcode primitives, microcode is presented as higher-level languages, and so on. At each level, simple elements are presented that abstract away the complexity of the operations underneath.
Modern software development primarily involves synthesizing a variety of external elements: open source software, third party services, infrastructure APIs, and so on. We bring these together using code to create our systems. It is a world of composability, and our systems are mixtures of modules glued together with code.
Ideally, we would like to have elements that are designed to be used as primitives. Read the literature going back 50+ years, and you find the same good architectural advice: practice modular design—create primitive building blocks by strictly separating implementation from interface. “Don’t mix the paint!”
This is the logic that drove the development of AWS—offer customers a collection of primitives so they can pick and choose their preferred way to engage with the services, not a single framework that forces you into a specific way of working, which includes everything and the kitchen sink.
Of course in practice, at scale, it’s not that easy. See Hyrum’s Law, which says, with a sufficient number of users, all observable behaviors will be depended on by somebody. In other words, there is no such thing as a private implementation. We want to pretend that everything underneath the interface can be hidden away, but it’s not really the case.
If only we could rely on our interfaces like the artist relies on the laws of chemistry and physics. But the things we build with are much less dependable. Accidents can happen many layers underneath our work that result in massive change all the way up the stack (see Spectre or Meltdown).
Implementations also need to change over time, as we learn about our systems, their users, and how the users use them. What we are implementing are ideas about how to do “something,” and these ideas can and should change over time. And here we come to our second type of primitive.
Primitives of Semantics
Every software system is a solution to a problem. But if we start with assumptions about the solution rather than clear statements of problems, we may never figure out the best use of time and resources to provide value to customers.
Even if we had a crystal ball and knew exactly how to solve our users’ problems, it would still not be enough. We also have to know how to get there—a map of the the increments of value to be delivered along the way. We need to find stepping stones to a final product, and each stone must align to something a customer wants.
How do we do this? Again, we try to work from indivisible elements. I like to call these “semantic primitives.” We want these, our raw materials, to be discreet and independently evaluable. Again, “don’t mix the paint!”
These are implemented in various ways. The word “requirements” gets a lot of hate these days. “User stories” are popular, but “use cases” have fallen out of fashion. After a blog post on Medium, “jobs-to-be-done” became “the framework of customer needs” seemingly overnight.
Regardless of how you conceive them, the purpose is the same: to serve as building blocks for understanding the problem we want to solve and to help us be creative as we move along our product journey.
When starting with a set of semantic primitives, we can learn from one, make mistakes with another, fall over a third, pivot between the rest, and so on. In theory, they allow the development process to become changeable and continuously aligned to delivering incremental value to customers.
But again, in practice, they are challenging to work with. These are not exhaustive proofs or laws of mechanics. They are assumptions and estimations, usually based on poorly sampled probabilities and questionable causality, crafted loosely with a lot of grey language. And they have to be, because our understanding of our customers and their problems is necessarily incomplete.
Synthetic Systems
Let’s go back to the difference between “red” on paper and “red” in your mind. On paper, the color is stable, it is factual and replicable. But in your mind, the color is unstable and ambiguous. This is the world of objects vs. the world of our minds.
In software, we don’t have the luxury of primitives with stable dynamics like those found in the world of objects. Our systems are synthetic, made up of cognitive composites that are subject to change without notice. We work only inside the world of our minds.
The system dynamics we observe today may not be the same we observe tomorrow. The semantics that we wrote down today may no longer be valid tomorrow. We live in a world of constant uncertainty and emergent knowledge.
To work with such uncertainty, we need to adopt a corresponding mindset.
A big part of the journey in software is learning to suspend the heuristics and mental models that we rely on when interacting with the world of objects. Getting burned by misplaced trust or untested assumptions is part of the evolution from junior to senior.
So we learn to think differently, we learn to challenge everything we see. But is this enough?
It’s worse than we thought!
In his book, Thinking Fast and Slow, Daniel Kahneman talks at length about the ease with which we fool ourselves into believing in improbable outcomes, and how we are particularly susceptible to illusions of cognition.
Take the example of The Dress. After learning about this visual illusion we easily adjust our understanding. Once we know the truth, we correctly say that the color is black and blue, even though our eyes may still deceive us. We do this by consciously doubting what is presented.
But when it comes to illusions of cognition, it’s a different story. Evidence that invalidates ingrained thinking is not easily accepted. Look to the Dunning-Kruger effect, or even anti-vaxxers and flat-earthers for some extreme examples. This does not bode well for us.
Just like the professional artists that are surprised by Albers’ color studies, even the most grizzled veterans of software delivery will make surprisingly incorrect assumptions about their systems, about whether things will work, whether they will continue to work, whether they create value, whether they meet customer needs, and so on.
And it’s no wonder—living in a world of constant conscious doubt is hard. It demands a lot of energy. We have to be unrelenting to resist the urge of falling back on the heuristics we learned from the world of objects.
Conscious doubt creates cognitive strain, and doing so constantly is a heavy burden. This is probably one reason why software development has a high rate of “burnout.” So what do we do?
Systems of Synthetic Management
Let’s restate the problem:
Our materials (code, interfaces, requirements, etc.) are derived from unstable primitives.
To use our materials, we need to adopt a mindset of challenging everything.
We can’t trust ourselves to consistently use that mindset.
The solution? Systems.
We can use systems that manage the uncertainty for us, that create bounded contexts of risk and bring new knowledge to the foreground as it emerges.
We have the incredible power of programmability. We can invest heavily in the gifts given by the medium of code. We can construct elaborate systems of test automation, continuous integration, and production monitoring to unrelentingly test every one of the assumptions we make about how things are supposed to work.
We have practices of agile, lean, and design-thinking to guide us in managing our semantics. We have developed methods driven by research and statistics to generate better primitives. We can work iteratively within boundaries that limit the scope of inevitable errors. We can use these practices to find metastable states that enable us to move forward.
We are still maturing these systems of synthetic management, developing the competencies required to manage and control our work’s synthetic nature. It pays to remember that it has been only 20 years since the discovery of Agile and even less since the word DevOps was coined. Our field is new, and we have not yet mastered these ways of working, though of course we easily slip into cognitive illusions that convince us otherwise.
All kinds of work involve overcoming illusions. But software has the added burden of resisting the siren’s song of a stable world of dynamic and semantic primitives. Fortunately, we can create systems to escape from it, and the development of those systems will define our success in delivering value with software.

























{kind=link}