What does it mean when we say “Flow”? In the study of organizational dynamics and productivity, the concept has evolved significantly over time. We can see three distinct yet interconnected types of Flow that have shaped our understanding of creativity, efficiency and productivity in various contexts. Let’s review them (using some names I made up) and then look at a new book, Flow Engineering, that will help you apply the principles of flow to your organization.
1. Psychological Flow
The oldest form of flow, psychological flow, was popularized by Mihaly Csikszentmihalyi in his seminal book “Flow: The Psychology of Optimal Experience” where he describes the mental state of an individual when fully immersed in a task, experiencing a sense of energized focus, full involvement, and deep enjoyment in the process.
This state is personal, individual, and is characterized by:
Complete concentration on the task
A sense of immersion in the work
Great inner clarity and knowing what needs to be done
A sense of serenity and timelessness
Intrinsic motivation, where the experience becomes its own reward
This form of flow is associated with artisans, athletes, and creative professionals who lose themselves in their work, achieving a state of peak performance in their deep focus. It harkens back to the old days of craftsmanship when goods were created only through the highly refined expertise of master workers.
2. Systemic Flow
As we moved into the industrial age, the concept of flow evolved to encompass entire production systems – the coordination of processes to enable people and machines to work together at scale, producing goods en masse. Systemic Flow is exemplified by the Toyota Production System and Lean manufacturing, and focuses on optimizing whole systems to achieve consistent results, high quality, and reduced waste.
Key aspects of systemic flow include:
Visual management
Just-in-time production
Continuous improvement (Kaizen)
Standardized work processes
Pull systems
This approach aims to create smooth, uninterrupted processes by minimizing bottlenecks, reducing inventory, and maximizing efficiency. It’s about creating a rhythmic, predictable flow of work through an entire system rather than just the experience of individual contributors.
3. Cognitive Flow
As we’ve entered the information age, a new form of flow has emerged that combines elements of both psychological and systemic flow and applies them to the context of socio-technical systems – humans and computers working together as a collective cognitive system to deliver the “invisible” work of the information economy. It recognizes that in modern knowledge work:
Information and decision-making flow through networks of people and computers
Work is often non-linear and requires constant adaptation
Creativity and problem-solving are as important as efficiency and consistency
Collaboration and communication are critical to success
This new paradigm seeks to create environments where people can give their best inside complex systems of technology and process, fostering innovation while maintaining efficiency. It incorporates ideas like:
Agile methodologies in software development
DevOps practices that bridge development and operations
Design thinking approaches that emphasize empathy and iteration
Data-driven decision-making that leverages both human insight and artificial intelligence
Value stream management to connect all the activities required in end to end delivery
Cognitive Flow defines the modern era of work, where we need to harness the mechanistic elements of scaled systemic flow with adaptations needed to enable human creativity and craftsmanship at every stage of the delivery process.
Flow Engineering
In their new book “Flow Engineering”, Steven Pereira and Andrew Davis lay out the fundamentals needed to engineer our systems of work for cognitive flow. It captures the state of the art in improving organizational performance when working on information systems at scale, systems where we need to find harmony between personal mastery and organizational systems, centralization and decentralization, planning and uncertainty.
I appreciate that the book does not presume to cargocult a set of practices into any organization. The thrust of the book is how to use a set of calibrating mapping exercises to understand and improve the structure of your specific business and its delivery flows. There are five key maps that create interactive visual representations of flow to help you figure out how to manage it:
Outcomes Map, to discover and align on value
Value Stream Map, to find and measure key constraints
Dependency Map, to connect constraints to dependencies
Future State Map, to design an improved system of flow
Flow Roadmap, to create and plot clear next steps
Engaging in these mapping exercises provides a basis for applying the principles of flow in your organization, bridging the visibility gap inherent in knowledge work to create a foundation for managing, leading and scaling flow across teams. If you are looking to understand how to execute on achieve cognitive flow in your organization with a practical set of actions, this book is the place to start.
The Evolution of Flow
The progression from psychological to systemic to cognitive flow reflects the changing nature of work and organizational structures over time:
Psychological flow emphasizes individual mastery and the joy of craftsmanship.
Systemic flow looks at the entire production system, optimizing end-to-end processes for efficiency and consistency.
Cognitive flow seeks to create systems that are both efficient and adaptable, leveraging human creativity alongside technological capabilities
As organizations continue to evolve, our understanding of flow will continue to adapt. The key is to create systems that not only optimize for efficiency but also foster the conditions for individual and collective creativity, learning, and growth.
At Enterprise Technology Leadership Summit 2024, Steve (co-author of Flow Engineering) and I will be presenting on a unique area in Flow Thinking: applying concepts from computer networking to improve Flow in organizations! Let us know what you think!
In many ways, the breakthroughs that have shaped the last few decades of progress in software delivery have become normal. We are no longer facing an intellectual gap in what “good” looks like on a software delivery team. DevOps has a Handbook, SRE has a Workbook, and Agile is even taught by PMI. We have an understanding of the core practices needed for teams to deliver software and a broad acceptance of their principles, tools and benefits.
While we will continue to see refinements, specializations, and new additions to our repertoire, our ability to leverage advances to solve very large problems depends on something far greater and more pressing: developing the leadership and organizational acumen to manage the complexity of integrating and adapting techniques, practices and technologies into different contexts at scale.
As a sign of the times, take the recent renaming of the premier technology conference, the DevOps Enterprise Summit, which will now be called the Enterprise Technology Leadership Summit, along with the accompanying Journal. This is a community that has long showcased the most thought provoking topics from high-performance technology leaders, the people who gave us game-changers like The Phoenix Project, Accelerate, Project to Product, Team Topologies, and, most recently, Flow Engineering. The name change is not a shift in strategy, it is a recognition of a fundamental reality: the core challenge of large-scale software has always been understanding how to manage the complexity of social-technical systems.
This is a difficult problem, requiring leaders to not only become experts in a variety of practices and technologies, but also to harness the organizational systems and behaviors required to adapt and integrate them into a particular organization, to fit their specific needs, culture, and scale. Factors such as organizational design, system architecture, legacy technology, regulatory requirements, market forces and much more will all influence how we go about implementing and achieving the goals of our ways of working.
While it is necessary to keep applying, refining and evolving individual practices, it is not sufficient. Organizational proficiency in enterprise technology management lies in leaders with a mastery of how to execute techniques like dynamic learning, flow systems, complexity science, transformational leadership, and much more. It involves understanding how to leverage the qualities and characteristics of socio-technical systems to capitalize on their form and capabilities, creating environments that enable progressive thinking to thrive.
And, of course, it means adopting new technologies to support our ways of working, most significantly Generative AI. Without a doubt, Gen AI is going to radically alter how we approach problem-solving in organizations. It is already producing a surge in creative thinking about how we engage with our systems as people explore different ways to leverage AI capabilities, learning how to build things better by augmenting our human abilities.
Interestingly, the challenge of deploying Generative AI for productivity is much akin to the problem of deploying DevOps or Agile. On the one hand, it requires learning the ‘where, when, how, and why’ of the phenomena, but on the other hand, and equally important, it involves the same core element described above: the ability for leaders to understand and execute on the ‘fundamentals’ of socio-technical leadership, to build organizations that are dynamically evolving and adapting to the possibilities presented by a new phenomenon. That is why ideas like those found at the Enterprise Leadership Summit are so valuable – we find the same keys to success needed to deploy any new critical, game-changing capability.
Today, we are at the “What is this?” phase of Gen AI, as we were with Agile twenty-something years ago and DevOps just ten. This will undoubtedly be an area of intense growth and significant opportunity for us all, and it would appear we are moving much faster into the scaling and integration phase of the problem. It is these topics and more that will be discussed at the upcoming Enterprise Leadership Summit in August, where I have the honour to be presenting alongside many esteemed guests. Hope to see you there!
Generative AI (GenAI) promises transformative potential for enterprises, yet the path from idea to implementation is complex. How can we harness this game-changing technology in the ecosystem of a large organization? We explore this problem in a new paper I co-authored and published in the Enterprise Technology Leadership Journal Spring 2024 edition.’
In this paper, my co-authors and I explore the challenges and opportunities that come with implementing Generative AI (GenAI) solutions in enterprise environments. We dive into key considerations for technology leaders, including:
The intersection of GenAI with DevOps practices
Essential technical building blocks for GenAI implementation
Emerging platform opportunities to accelerate adoption
Real-world use cases from various industries
We aim to provide a practical understanding for enterprise leaders to navigate the complexities of GenAI adoption while maximizing its transformative potential. The paper covers everything from demystifying the core concepts to discussing security considerations and outlining platform strategies.
For the full paper and a deeper dive into these topics, please visit the link below:
As a long-time practitioner in the field of improving ways of working across organizations, I often find myself drawing parallels between the complex systems we build in technology organizations with other domains. One area of deep interest for me is understanding the elaborate networks of people and processes in our businesses. This led me to collaborate with my colleague Steve Pereira on a paper that explores an idea I am passionate about: can we apply the principles of computer networking to improve how our organizations function?
In our paper “Wiring for Flow,” Steve and I dive into this concept, exploring how the strategies used to manage complex computer networks might help us address challenges in large-scale organizational systems.
The application of networking concepts like modularity, topology, and convergence to organizational design
The importance of layered models for effective communication across an organization
The need for balance between centralized and decentralized approaches to information management and decision-making
Our goal is to offer a fresh perspective on organizational design, blending insights from technology and management theory. We want to challenge readers to think about their organizations as dynamic networks rather than static hierarchies.
While our ideas are largely theoretical at this stage, we believe they open up exciting possibilities for new approaches to improving organizational performance, communication, and adaptability.
If you’re interested in innovative approaches to organizational design and management, I invite you to read our full paper in the Spring publication of the Enterprise Technology Leadership Journal. We’d love to hear your thoughts and experiences in applying these concepts in your own work.
How can R&D leaders working on incubation projects in large enterprises increase their odds of successfully transitioning into a major revenue stream? This article lays out the four enablers of transformation: Re-Use, Integration, Standardization and Unification.
Incubating Innovation: The Theory
You are likely already familiar with the Pareto Principle, also known as the 80/20 rule, which predicts that in complex systems, 80% of outcomes will originate from just 20% of sources. We find the Pareto Principle operating all over the business world. For example, a company may sell many different products, but often we see ~80% of their revenue coming from just ~20% of the portfolio. What, then, we must ask, is the other 80% doing?
In the large enterprise, we see dozens of businesses (each with their own 80/20 distribution) exploring hundreds of opportunities across thousands of ideas that could arise from anywhere in the organization. We are constantly trying to find a transformative product, the next source of immense revenue. However, incubating these ideas into full-fledged products is challenging.
Even when executing well, valuable innovations get dwarfed in the numbers game. A product with dozens or hundreds of customers growing 20-50% YoY would be a hit in the start-up world, but it’s just a speck compared to the monster main line of business. What this means is that these innovations are not the focus of the business. They are opportunities, yes, but they are also distractions, perhaps a nuisance, maybe even worse.
Here lies the much-discussed Innovator’s Dilemma. How should the business go about investing in new products without disrupting the existing ones? Not only do new products require diverting capital away from the cash cow, but these products will also compete for time, money and attention from customers, sellers and the core business. When there are other higher target, higher margin products that can be reliably sold, it is difficult to change focus to the new thing. So, how do new products make the jump from the long tail into the 20%?
Geoffrey Moore (of “Crossing the Chasm” fame) proposes solving this with the Zone to Win framework, wherein smaller bets are incubated off to the side in an “Incubation Zone”, and then transformed into the main business when they are ready to scale. The Incubation Zone gives a space for the product to exist without a lot of pressure from the main business. Eventually some ideas (or the market’s readiness for them) become mature, and then we can begin the process of moving into a “Transformation Zone” to turn them into major revenues streams.
The Zone to Win incubation/transformation strategy holds up under theories of probability, the same theories that underly the Pareto Principle. The model implicitly leverages Taleb’s Lindy Effect, which can be summarized simply as this: the longer an idea survives, the longer it can be expected to live. For intangibles, the expected lifespan can be inferred from the current lifespan. We can leverage this by putting the innovation into a “zone” that serves simply to keep it from getting clobbered. Stickiness through existence. Just don’t die. We won’t see a meteoric hot streak because the product is not supported by the main business yet, but that’s ok because the alternative is simply fizzling out into nothingness.
So the theory is sound, but how does it hold up in practice?
The reality is that attempts at innovation need to breach the ground truth of the Pareto distribution: when you are sitting in the long tail, there are forces working against you from moving out. I’m not saying there is some malicious intent, but it’s simply the nature the beast: moving a revenue stream up the curve requires significant energy to overcome many different challenges across Engineering, Product, Sales, Marketing, Support, and more. This is energy that is needs to be channeled and diverted from elsewhere, which is the essence of what it means to “transform”. There are things we can do to make that transfer of energy easier (or harder, should we ignore them).
Enabling Innovation Transformation: The Practice
Given the above, our goal as leaders of innovation in a large enterprise is twofold: 1) build innovative products that solve problems in the market (of course), and 2) build systems that can transition into the business product portfolio. That second part is what I would like to address here – how to approach engineering our products so they are positioned to ride the Pareto curve instead of fighting it.
What can we do to increase the chances of success when transitioning innovation products in the large enterprise? Primarily, we are looking to ensure that the product will be able to fit into the overall Value Stream of the business, leveraging existing opportunities, assets, and market position. I have observed that getting the fit is eventually subject to four enablers that shape that fit: reuse, integration, standardization, and unification.
I call these The Four Enablers of Enterprise Innovation. Ignore them at your peril: while they are easy to ignore in the Innovation Zone, they will hold back any innovation as it moves toward transformation. Embrace them, and you can increase the surface area of possible successful outcomes.
Re-use – leveraging existing technologies in the company to solve problems
Integration – enabling integrations with other products
Standardization – designing your product to comport with the current portfolio
Unification – fully subsuming your product into an existing one
Let’s take a deeper look at each of these:
1. Re-use
One of the major challenges with innovating in enterprise software is the potential to create a complex web of dependencies that become very difficult to manage. It is hard to build new things quickly and have a big impact on a growing opportunity in your customer base when you have to rely on many other teams that are already in the middle of their own cycles or sustaining large established products. Joel Spolsky famously wrote about the how the Excel team in Microsoft wrote and maintained their own compiler under the credo “find and eliminate all dependencies”. Of course, eventually even Excel could not stand alone. It had to become part of a portfolio and even transform into a cloud product.
The consequence of “not-invented-here” syndrome is the “it-doesn’t-work-like-that-here” dilemma. When products do the same thing but in different ways, the result is difficult to address feature gaps, awkward user experiences, and poor integrations. Re-using components, technologies and interfaces introduces a dependency, yes, but it also ensures that your product will work the same way and have the same potential as other products in the portfolio.
Re-use initiates supply chain dynamics, meaning suppliers take on responsibilities that need to be managed, like handling feature requests, dealing with high-priority bugs on non-standard use cases, offering support channels, distributing releases, and so on. This does require an investment from the service/component supplier to enable it, and on the downstream team to manage it. When these dynamics are initiated up-front with clear expectations, they can be managed effectively.
In my group, we have re-used components from across the company very successfully. Each time, we are very clear on expectations with the producing group and have patterns established that draw on Inner Source principles to ensure that we know our needs will be met. The result is both accelerated development (because we don’t have to implement capabilities ourselves) and the ability to fit our products into the overall portfolio.
2. Integration
Integration is needed when two products solve an overlapping or adjacent customer value space. This might be because they do very similar things (“I already did that job over here, why do I have to do it again over there?”), or they do complementary things (“I want the job I did here to feed into the job I have to do over there”). Integrations power the entire software industry, and the “integrate-ability” of a product is a critical part of a successful market entry, allowing a product to become part of existing ecosystems. But this is not always easy to do.
Take a familiar example from consumer products: the ability to cross-post from Instagram and Facebook. This capability did not drop until a full 8 years from the date of the Insta acquisition. Today’s Instagram is still only lightly integrated with Facebook, with its own messaging system, among other things. These systems are almost completely independent in terms of their capabilities and their design, and I can imagine that breaking seals to enable the first integration was very difficult.
Why is integration so hard? Internal systems like a database or message bus are not intended to be exposed outside a specific sphere of development. There are many design decisions that restrict the interactivity of a backend system and make deep integrations difficult, much of which is intentional (security!). One of the hardest parts of integrating can be the lost assumptions and unwritten requirements that a system was built on, known to the people who built it but not documented. These create traps for teams that show up green, naively expecting things to make sense (they did … once). But of course, it is possible to build this capability from the outset, to create secure, accessible interfaces by designing our systems with integration in mind. Some core principles to guide us:
Modularity: Adopting a modular approach means we build systems from a set of composable elements that come together to form a system. Embracing this methodology is not only good engineering practice but also a great way to ensure your system can be integrated into the larger product ecosystem, making it easier (but not trivial) for other systems to come along and use them too. Your chances of integration go up by a lot.
API-first: Using an API-first strategy means that we expose our modular components using public interfaces, even for internal/private usage. This means that internal services interact with the same interface that an external service. Not only does this improve the integration potential of your product, but it also makes for more robust interfaces because we will run into the same problems that our users will, long before they run into them.
Semantics: Paying attention to semantics is critical. One of the more difficult aspects of big integrations is aligning what things “mean” across different products. The process of semantic normalization – figuring out how to match up the various identities, keys, and categories – is a difficult process that involves either expensive engineering efforts to re-architect, or building and maintaining shim layers, transformers and/or translators. Do yourself a favour and pay attention to how the primitives in your system match up with those in the mothership.
To that last point, one thing that makes integration easier is standards that are shared and embraced across products, which brings us to our next Enabler.
3. Standardization
Large enterprises sell a vast array of products that may be only tangentially related or have little in common with each other. Across the board, the company is leveraging its brand, its reputation and existing customer base to sell into and capture new markets. The business and its customers expect to engage with the product portfolio in a consistent way. When we make decisions that deviate from those expectations, or ignore them altogether, we will have major problems later on.
Standardization initiatives make it so that new products and services can easily slide into the DMs of the existing portfolio. In this bucket I put a variety of different areas that make the product comport with the existing portfolio. The rush to create a new product, and the opportunity to do it in isolation, means these areas are often missed by Incubation zone products. There is a wide range of opportunities to standardize with the larger business that are easy to implement at first but become very challenging to change once the product gets legs. Some examples:
Provisioning – once your product starts getting packaged with other products, you will have to interface with enterprise customer management systems. All those operations you do to set up a new customer org need to be automated, and you need APIs for everything from creating an account to enabling feature flags. As mentioned, above, taking an API-first approach to this problem in the beginning makes integrating with the existing enterprise systems a lot easier, and increases the time to value on a critical KPI – how quickly can you make your product packaged into a larger product suite and sellable by your entire salesforce. Simply using an API-first strategy on your customer management tools from the outset is not a big investment but will net big gains later on.
Design – Using an existing, actively-maintained design system for new products to use is a huge advantage, because re-skinning your product later on is a big investment. We may be faced with the dilemma of a lack of convergence on a enterprise-wide design or aging design decisions. In this case we can at least look to the existing product for inspiration and try to follow as closely as possible, modernizing where appropriate. It’s possible that your unique design system will get adopted when the product moves into transformation (seen it happen!), but its highly unlikely.
Developer Experience. There are two aspects to this: the developers in your company that can help you with your transformation journey, and developers outside your company (customer users) who are going to use your product alongside the rest of your company’s product portfolio. It is good to treat both of these as User Personas and consider them alongside the other personas that you are building for. Having a developer experience that deviates massively from everything else or which cannot be accomplished alongside the Developer Experience of the rest of the portfolio is a major setback.
These are just some examples of areas where we can leverage standardization to integrate our innovations sooner and more efficiently, there are lots of others though and I would love to hear your ideas on what they are.
4. Unification
Now we come to the big kahuna – bringing multiple solutions together in one place. When multiple products need to work together to form an overall solution, the customer ends up having to go to many different places to do their job. As products proliferate, each will have its own user interfaces, backend systems, and so on. This can reduce the value of the overall portfolio because it fragments the user experience and makes accomplishing a job end-to-end more complicated and challenging.
When a new opportunity enters the milieu, we have to consider the idea of unifying it into an existing property. Does it need to exist as a standalone product? Are there jobs-to-be-done in concert with other products? Will the customer be able to navigate through the cross-product solution to get the value they are looking for? These are good questions, and they deserve good answers.
They are such good questions, in fact, that every so often someone will have the idea that we should unify all products, i.e. have one place to configure everything, a single pane of glass with all the knobs where you can configure everything all at once. One dashboard to rule them all. The reality is that this is very difficult to execute on. You had five dashboards, now you have six. Most grand unification initiatives can be re-written with a few simple words: not going to ship. That’s because unification means migrations, and migrations are hard.
But what about unifying our new incubation product directly into The Big One? Can we bring these two things together and make them work as one? If we are following the above – standardizing, re-using, integrating, then the odds go way up. In fact, this is also a great start-up acquisition strategy: focus your attention on bringing your product as close as you can to your acquisition target, and it can work for you to when you want to bring your incubation product into the transformation zone.
A Note on Culture
It is important to note the role of culture and attitude in enabling transformation success. The way an incubation group holds itself in relation to the rest of the business is a big factor in its ability to successfully transform. A culture that has been built with a mentality of superiority, elitism or “other-ness” is not going to have the kind of relationships that are needed to take on the incredible challenge of joining the main product portfolio. These challenges require open-mindedness, diversity of thinking, appreciation for the role of others, and respect for what came before.
Conclusion
Engineering strategies in the incubation zone cannot ignore these realities – customers come to big companies looking for solutions to a wide variety of problems, and your sales teams are looking to solve them using integrated solutions. This means your product must take into account these elements, for better or for worse. Of course, we need to move quickly, however many of the above strategies are not costly to implement until you have to do them retroactively!
By approaching our engineering with these enablers in mind, you can increase the odds of success for your incubation products and for the entire business that we hope to create value for. Re-use, Integration, Standardization and the possibility of Unification: these are the things that bring down the costs and make investing in the transformation a safer and more optimistic bet.
In 1893, Frederick Jackson Turner penned his famous Frontier Thesis to explain the culture that grew from the unique circumstances at the birth of the American nation. It was the great Western frontier, he said, that gave rise to a particular character, driven by the struggle and opportunity that lies in exploring the unknown. The aspirational attitude of the pioneering lifestyle invigorated and energized society, fostering a set of values rooted in inventiveness, inquisitiveness and perseverance that would remain an integral part of their culture.
In the history of computing, we have seen many frontiers emerge in the form of scientific and technological horizons. They also shape our organizations and communities in powerful ways, and exploring them is part of our culture, bringing that same invigorating energy into our teams and organizations. It is not some neomania (the obsession with any and all things new) that drives us to explore emerging areas, but rather, it is the beckoning of the frontier – the urge to explore, to embrace the pioneering spirit, to go where the maps are not yet drawn.
The Frontiers of AI
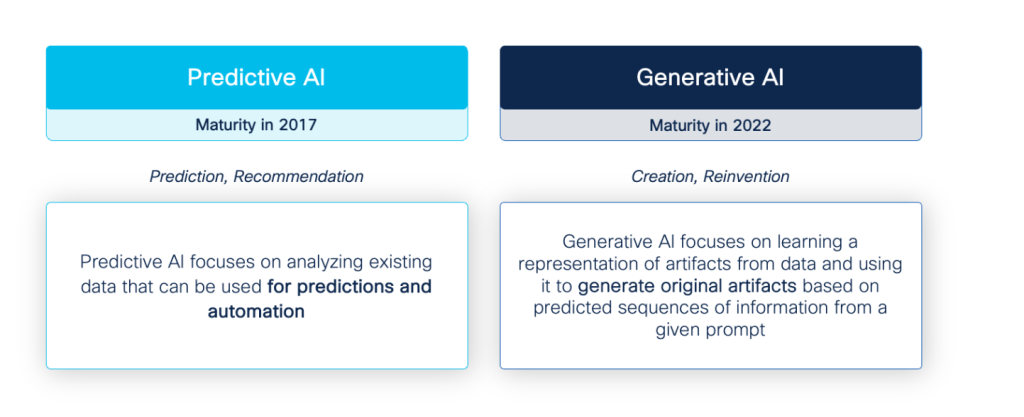
At Cisco, we have been engaging the frontier of AI for the better part of a decade. While the latest discovery comes in the form of Generative AI, it’s important to note that this is actually a facet of a larger movement in artificial intelligence driven by data science and machine learning that reached maturity years earlier. At Cisco, we make the distinction as follows:
As early builders, investors, and adopters of Predictive AI, we have implemented many features across our portfolio. For example, in Webex we have world-class audio, video and language intelligence capabilities deployed to do noise filtering, cinematic focus, automatic language translation, and more. Similarly, our security products are enhanced with AI-driven threat detection and anomaly prediction capabilities to make the world safer for our customers.
What makes the research and development exciting and unique at Cisco is a broad product portfolio that adds so many different perspectives to the learning experience. We are a key player in many markets and product categories, including Networking, Servers, Collaboration, Security, DevOps, Applications, Monitoring and more. All these groups in Cisco have made significant investments to create additional value for customers by building AI-powered features and capabilities across our portfolio:
As a result of all this work, Cisco has a large, distributed community of AI pioneers: architects, designers, scientists, inventors and visionaries who are already highly engaged in AI R&D. With our broad expertise across all these areas, we benefit from a diversity of perspectives found in different market forces, product visions, and technology opportunities. This makes Cisco a fantastic place to explore Generative AI: a fertile ground for growing knowledge and expertise in our new frontier.
Generative AI at Cisco
The new frontier is indeed invigorating for our business, just as Turner’s Frontier Thesis predicts. The energy from discovery and experimentation across the quickly evolving Gen AI landscape drives a collective and collaborative learning initiative across the company to share knowledge and improve our understanding.
We have formed a massive community of Generative AI explorers and specific communities of practice around topics like Conversational Agents, Security, Design, and so much more. We have multiple enterprise-wide Platform initiatives to make tools and knowledge available to everyone, helping teams build, ideate and experiment more quickly. Importantly, we have a well-considered strategic initiative to drive Responsible AI across all our products and help people understand what it means to deploy AI safely, securely and with applied ethical considerations. It’s a movement, an upswelling, and it is partly powered by our diverse product portfolio and our commitment to innovation and customer success.
My specific interest lies in how we will develop, operate and secure these Gen AI systems at scale. This question of how we will build Gen AI-powered systems is to me even more exciting than the question of what we will build with them. I guess you could say I am more settler than pioneer, driven by a passion for DevOps and “ways of working” that make this aspect of the frontier particularly invigorating for me.
To that end, I have been exploring the world of “LLMOps” and Platforms for AI, investigating what it means to enable teams to deliver LLM-powered features and capabilities at scale, and looking to understand what it all entails for Cisco’s customers, partners, employees and the global community at large. I look forward to sharing the new and interesting ways in which Gen AI will challenge us across our product delivery process.
This is a summary of my talk at DevOps Enterprise Summit 2023. To watch the full presentation, please visit the IT Revolution Video Library here: https://videos.itrevolution.com/watch/873538323
The advent of widely available Large Language Models (LLMs) has created a tremendous amount of excitement, and a decent amount of chaos.
Let’s face it: LLMs are a solution looking for a problem, but given how powerful they are, we are all looking to discover the various problems they can solve in our specific product contexts. What, then, are the patterns that we should be on the lookout for?
At Cisco, we have dozens of product and service groups that are working to harness the power of Large Language Models and Generative AI. We have a very strong learning community with a large number of AI enthusiasts, many of whom already have years of experience shipping AI capabilities using machine learning and data science. I am grateful to have the opportunity to connect with this community to learn what people are doing and how they are using Large Language Models in their products
From these discussions, I see some broad product patterns emerging, which I have captured in the form of the following archetypes:
The Vizier, “How may I help?”
The Judge, “Here’s what I think … “
The General, “ Tell me what to do!”
I like to think of these archetypes as forming a royal court, a council that gathers to help you rule the realm (your product) and take on some of the difficult work of serving the people (your users). Each member of your council plays a different role. While they are all devoted to you, they think and operate in different ways. Let’s dig in.
The Vizier
The first pattern I call the Vizier. They are trained on a body of knowledge that we want to give people access to. “How may I help?”, the Vizier asks, who is here to make sense of challenging problems, a Socratic partner of sorts. They will answer questions to explain complex material or help turn an intention into an appropriate course of action. The Vizier may be an advisor to you, or they may go directly to the people and help them with their problems. The Vizier is always ready and waiting to serve when called upon.
In this pattern, the user interacts directly with the LLM to get access to information available in the model. It is an inboundworkflow, where users are deliberately and knowingly interacting with an AI. The pattern is usually implemented as either a conversational agent or co-pilot. The distinction between the two is important — a chatbot-style agent has an open, natural language interface, while the co-pilot is constrained to making suggestions that guide the user through a task or workflow.
This pattern is obvious and prevalent, typified, of course, by ChatGPT. Most companies will already be looking at possibilities to simplify their product experiences or enhance self-service workflows using The Vizier. For example, at Cisco, we have a vast body of training materials that customers need to understand their products. Simplifying access to that information is a real, tangible, and immediate benefit to our customers, and it is one of the first and earliest Gen AI capabilities we have launched. In fact, we now have a Vizier-style agent that interacts directly with users in our forums (we make sure to let users know they are interacting with a bot, of course).
The Judge
The next pattern is The Judge. Here we have an expert who can look at a situation and use their training to provide opinions, summaries, and judgments to our users. “Here’s what I think”, says the Judge, who is adept at boiling down a complex set of facts into something that is understandable and useful. The Judge can sometimes get things wrong though, so we may need to review their opinion before actually presenting it to the user, perhaps by a jury of their peers (i.e. other LLMs), or even our user’s peers (other humans). Sometimes, we do not agree with their decision, so they need the ability to appeal and ask for a new judgment.
In this pattern, we take a user’s situation and interpret it through an LLM. This is an outbound workflow, where the user generally does not get to interact directly with the Model — we are providing them with the output of the model to meet their need for a specific context. We do need to disclose to the user that the content is AI-generated and warn appropriately so they can inspect it and assess it accordingly. We may allow the user to regenerate the content in a different way if the results are poor, and we need to collect feedback so that we can continuously improve the quality of the output and use it in reinforcement loops.
This pattern shows up anywhere we want to help our users by generating the content they need to complete their tasks. The main activities are summarization, completion, and categorization. Examples include summarizing the recording of a meeting into a set of notes, boiling down a case into a summary, or analyzing a dataset for patterns. I would also put the coding use cases under this category, like Github Co-pilot, which I would actually not call a ‘co-pilot’ as it is really a completion pattern in the style of The Judge.
Sidebar: it is interesting to note that both the above patterns also call upon new design patterns in our products. Normally products are supposed to get things right — if we cannot get it right, why would anyone use it? But here, we are generating original content, and the user’s opinion of it is subjective, so we can give the user controls to generate content differently to meet their expectations. For example, Midjourney offers interesting methods to recreate your picture without changing the prompt by adding more or less variance, expanding or changing the perspective, and so on.
The General
The final pattern is the General. Here we have an agent who can help you execute your plans. “Tell me what to do!”, the General says. Give them orders, and they will carry them out to the best of their ability, returning dutifully with the results. The job must be done correctly, and there is a right way and a wrong way to do it. We have to make sure that the General is extremely well-trained on the tasks being given because the stakes are high and there is a lot on the line: coming back with the job done wrong means the plan will fail. We also need to have a robust system in place to ensure they complete their task correctly.
In this pattern, we are placing the LLM in a workflow and using it to accomplish some or all of the steps in that workflow. It is a backend workflow because the user does not know that the LLM is involved in what they are doing. The LLM is being used as a kind of engine that can take an input and produce the desired output needed for a sequence of operations. Andrej Karpathy has started calling this the “LLM OS”, which is an interesting way to think about it. The goal is to improve a workflow by generating output that can be used in downstream operations.
In this pattern, we are incorporating operations like classification, categorization, labelling, and translation into a larger workflow. For example, in security products, we may want to categorize a document so that we can decide whether it is content that needs to be blocked. The user creates a policy to block malicious or unwanted content, and we will use the LLM to classify it as such. Clearly, if we start blocking content that should be allowed we will cause problems for end users, worse is if we allow content that should be blocked.
The General holds a huge amount of promise if we can get it to work. The opportunities are truly incredible. However, right now it is also the pattern with the most difficulty. There are a few problems:
The probability problem: we need to remind ourselves that an LLM is a probability engine, not a logic engine, and there is a non-zero probability of generating the “wrong” answer. We are building workflows that need to have a guarantee of accuracy. What level of correctness are we okay with? What happens if the model is incorrect? In what ways can we check and monitor “correctness”?
The explain-ability problem: it is difficult to ascertain why an LLM has arrived at a given decision. This is problematic because when we have a failure in reasoning, we don’t know why it happened or what we need to do to correct it. Is there a problem with the data? In the model? In the embeddings? In the prompt? When you change these things, how do you know if you are helping or hurting the model? Again, how will we test and monitor the correctness?
The data problem: We’ve been collecting data for years, so there must be lot of it to feed the LLM, right? Wrong! A lot of the training data that we need to do these tasks just isn’t there. Most datasets do not contain all the contextual details that are needed for Generative AI: before LLMs came along, we would usually not store the whole documents and lengthy descriptions that an LLM needs to train itself, just the metadata.
The drift problem: over time, our world may no longer match the world that was captured by the LLM. At some point, the meaning of words will change, categories will expand or contract, and new concepts and ideas will enter the milieu. At what point this happens is never certain, nor is it clear how we would introduce these changes into the LLM. This means that the training we give the General today will drift from reality over time.
While Generative AI has proven incredible at (surprise!) generating content, using LLMs in logical workflows is still an area of exploration. With the Vizier and the Judge, the output is presented for interpretation by the user, and acceptable answers fall within a range of responses. We can let users play with the output to get what they are looking for. With The General, the constraints on “correctness” are strict — right or wrong. It appears that LLMs will take some time to mature in this area.
LLM-Powered product development is coalescing into a set of standard implementations. These patterns identified here are a first cut at trying to understand the broad strokes for LLMs in our applications. What nuances do you see in these archetypes? What would you add or change? What other archetypes do you see emerging? Let me know what you think here on LinkedIn or on X @jrause.
The current discussion about security AI is all about the prompt, a natural focal point: it’s the interface, generally available to the public and evoking the world’s imagination. We can already see the weaknesses: the ability to generate malicious content, the problems of data privacy, the threat of injection/exploitation, and general adversarial dialogue. But this is not what I want to talk about – I am interested in what is underneath.
I am interested in how we will operate our own deployments of large language models, and what happens when people start attacking them.
As corporations begin to leverage in-house LLMs, this will become a primary concern. And make no mistake about it: this will be the only way that many large businesses will be able to run AI with their own data, in the same way that we run on-prem versions of tools like Github and Jira, for the same reasons that Apple, Samsung and others have blocked their employees from using it. In fact, we just shipped a blocking capability in our own security product here at Cisco.
It’s true that, for access to large and powerful LLMs, subscription providers like Google, OpenAI and Anthropic will remain dominant for some time. But with an increasing push towards open access models (thanks Meta!), a deluge of new developments to run models more efficiently, and constantly emerging techniques like fine-tuning, distillation, and quantization, we can expect the reality of “LLMs for everyone” to arrive sometime soon. Over the long term, there is no moat.
When it comes to operating and securing our own models, what we need to contend with are the novel elements that are introduced with this new technological paradigm. The pattern at hand is this:
With new technology comes new patterns of insecurity
Think about it: email, databases, websites, the internet. All of these technological paradigms, when first deployed, were deployed and operated completely insecurely. In fact, when they were first deployed it would take a crystal ball to even understand what “insecure” even means in the new context. It is not until we actually see technology being used at scale that we discover the many ways in which we misunderstood it and its edge cases.
And, of course, what happens when we come to rely on a new technology? It becomes the target of attacks: to disrupt the business of a company, to steal or falsify information, to undertake malicious activity in a variety of ways.
Today, very few people would know what it takes to run your own LLM in production, and even fewer know what parts of it are subject to interference, meddling or unreliability at scale. But we can change that. It is easy to get a toy system running quickly on your computer so you can start to understand the different elements of the system. We can play around to get a feel for how to deploy and operate models, and start to understand what is to come in the world of LLM security.
LLMOps
Let’s imagine we want to deploy an LLM internally to help unblock employees on their day-to-day tasks. In particular, we want to give our coders access to a tool that will make them more productive without exposing data to a service provider.
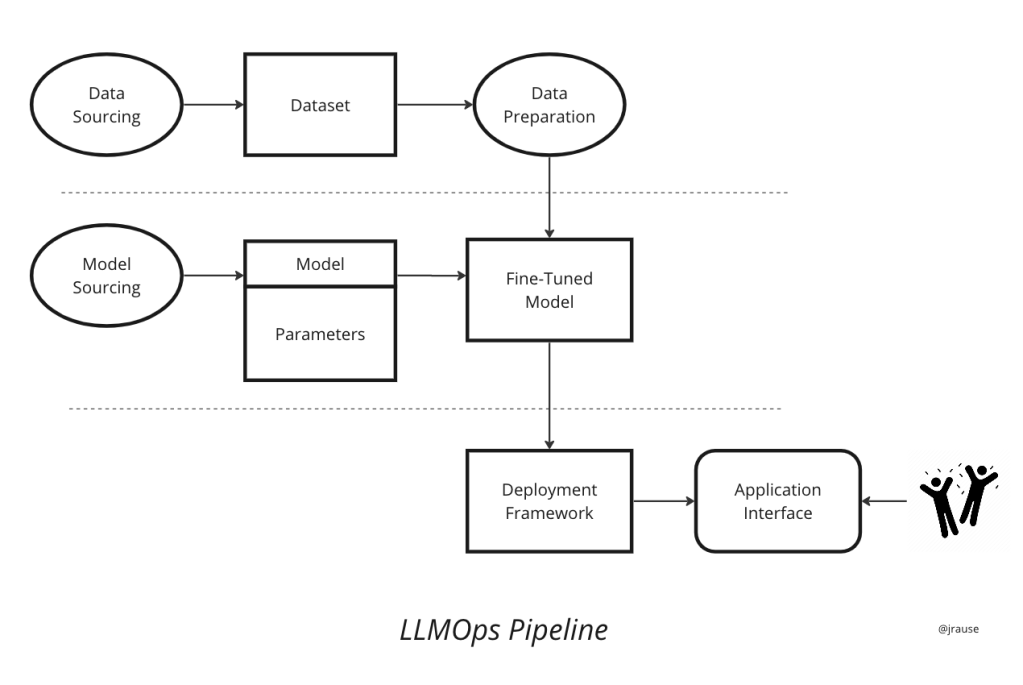
For this, we will want to provide an LLM-powered internal application that is optimized for generating code and which also knows about all code and code-related artifacts within the company: where they are, how they are organized, who wrote them, and so on. To do this we will need to give it access to every internal repository in the company as well as the documentation (internal and external) around it, and we will want to update it regularly on new materials so we can use it to come up with fresh insights. What do we need to do to get this going?
The Dataset. Our own data, our crown jewels. It is going to be ingested regularly, so we will need a continuous sourcing pipeline from the relevant data sources. This means crawling doc stores, connecting to raw data sources, and then properly cleaning up and tokenizing the data. Data preparation and refinement is an area that is already mature, but note that there are aspects of the transformer architecture in our LLMs that cause the choice of tokenization techniques to uniquely impact the performance of the system.
The Model. The model is the structure of the learning machine that will do our inferencing. The models we are using today are neural language models that have been around for a while, but the transformer architectures and their self-attention mechanisms are a recent breakthrough that has caused an explosion of interest in AI. This is fueling a fast-growing community of contributors from which we can source our model. This also means that, for whatever model we choose, we will likely want to change it in the near future, so we need to support easily testing and swapping new ones.
Parameters. Our model needs to be trained on an initial dataset that will generate the parameters used to make inferences. Training is very expensive, and we will not be doing it ourselves: we will use a pre-trained model that comes with an existing set of parameters. Parameters number in the billions. The files can be huge (tens to hundreds of gigabytes), are loaded into GPU memory, and can be challenging to deal with. In our example, we will take an open-access model like StarCoder, which is pre-trained on a large coding data set. The model was trained on 512 NVideo A100 80 GB GPUs, however you can run it yourself on a single A100.
Fine-tuning: This is the process of adjusting the model’s parameters to optimize it with our own dataset. Though not as intensive as the initial training that we get for free, it can still be significant and requires specialized hardware. We will need to build the capability to do automated retraining of our models for several reasons: the first is to update our model as we acquire more data. The second is that, in general, models are susceptible to degradation over time. Model performance SLIs like accuracy, recall and latency must be monitored and tracked to identify such issues and retrain when necessary.
Framework: These tools and libraries help us run our LLM in production and make it available via a set of APIs. Frameworks like these will help load and unload our models independently from the actual user interface. Frameworks also take care of optimizations like layer fusion, precision calibration, and kernel auto-tuning that help deployed models run more efficiently and effectively in production environments. There also are many different scaling and performance implications here, depending on the number of users and the amount of activity.
Interface: this is the actual application experience that our users will have, provided through APIs and UI, serving up our precious prompt, which we have all come to know and love so much.
We call this process LLMOps: the pipeline to continuously leverage updated datasets, evolve models, fine-tune parameters, and continuously deliver our system.
We will need to be able to quickly and easily version, test, verify, upgrade, swap, monitor, and deploy all of these components. We will also need experimentation infrastructure in place to allow us to try different models, test our fine-tuning, and evaluate/validate the results with real people using A/B strategies and control groups. With these capabilities in place, we will have a continuously evolving process that allows us to iterate on our internal LLM deployments.
We are already seeing many vendors entering the LLMOps space to help companies more easily handle these tasks, and leading the pack is Hugging Face with their amazing toolset and model zoo. While many bottlenecks in the current process make the state-of-the-art cumbersome and unwieldy, the industry as a whole is moving forward very quickly, and we can expect to see production LLMs proliferate in the coming years.
Security
Now that we have a model of our LLMOps pipeline, we can ask the pertinent question – how might an attacker exploit it? Little has been published so far on this topic.
Based on my research and experience with running small models, I’ve started to think of a list of potential attack vectors, but please note that this is really just a thought experiment. It’s a good way to start, but as stated earlier, we also will have to wait and see what attacks emerge as these systems start getting used in production.
Dataset Attacks: The dataset has obvious security implications, and it will be a main target for attacks, not only for data theft but also for poisoning attacks in the preparation process. This would be secured using traditional data protection methods, which I would characterize as a mostly solved problem in the existing infosec domain. Like any dataset, ours is highly sensitive, so this area needs to be handled carefully.
Malicious Models: For the model, we need to consider malicious model attacks and understand the tampering/repudiation dynamics in the model supply chain: how we can validate that our model is not malicious, that the model we downloaded is the legitimate model, that the model has not been tainted in some way, containing exploitation code or somehow re-trained.
Parameter Poisoning: Various attacks could be made on the model parameters used to make inferences, forcing them into misclassification patterns. Parameters degrade in a number of ways that can deny service by making inferences useless or misleading.
Hyperparameter Interference: We need to consider a variety of denial-of-service attacks that involve the hyperparameters of both the model and the fine-tuning process. In this way the system can be de-optimized to the point of making it useless.
Framework Disruption: the infrastructure we use to deploy our model is also vulnerable. There are model inversion attacks that can reconstruct the training data from the model parameters, and there is the potential for the model to be altered and made unusable or otherwise non-performant. The model itself could also be replaced with a different one manipulated to behave in unwanted ways.
Interface Attacks: In our example, the application interface is for internal use only, and therefore we need to ensure secure access control is in place. There are already great ways to protect internal applications using Zero Trust Access with IPS, DLP, and more (this happens to be the product I am building in Cisco right now). In the case where the interface is exposed to external users, then we need to be more concerned with prompt injections, data leakage and other attacks, which is a topic that is already covered elsewhere.
Overall, empowering our businesses with in-house LLM means developing a good understanding of LLMOps, and creating a taxonomy of vulnerabilities for the LLMOps pipeline. Some resources that I have found interesting as I start my own journey:
First, for a comprehensive list of AI resources, nothing beats A16Z’s new article, AI Canon.
On LLMOps check out (note that these are mostly about working with SaaS offerings):
Finally, you should definitely check out the papers for the major models like BLOOM, LLaMa, Vicuna, GPT-4 understand how they are built, and of course, head over to Hugging Face to run your own models and play around with them.
The potential for the proliferation of in-house LLMs is increasing every day. Expect this to be a ripe space for investment as AI adoption increases. As their value is proven, we will see both LLMOps and LLM Security become exciting ecosystems with their own hype cycles. You can get ahead of the curve today by experimenting on your own. If you do, reach out! I would love to hear from you.
Sometimes it feels like we are swimming in a giant sea of products, people and teams. Other times we forget that there are oceans of activity going on all around us.
Developing software in a large company comes with a unique set of challenges. For a small engineering team, having an org-scale impact can be intimidating. If you are leading a small team in a large organization, it helps to have some heuristics to guide you.
In my own experience with navigating the seas of large-company life, here are some of the things that have helped put wind in the sails of my teams:
They Value Relationships
Relationships are the most durable thing in our industry, which is otherwise characterized by a fast pace of change. Relationships survive re-orgs, resignations, product pivots, budget cuts, rapid growth, layoffs, acquisitions, downturns, expansions, you name it. But they need to be formed early and nurtured — they are built over time, not the week before you need something.
No team is an island. To be successful, you need to work with a network of teams that delivers value together. Take the time to map out your partners, dependencies, and the value stream of your product: you will discover the key people you need to work with now and in the future. These are the people to invest in building relationships with.
Development gets most deeply and intractably stuck when something is needed from somewhere else, but there is no relationship in place (or maybe a bad one). Many of the most significant slips and falls I have seen result from teams that go deep into the darkness of development, meanwhile forming unreasonable expectations of entities on the outside. Then they are surprised when no one is aligned with their needs when the time comes for needing help. Don’t be that team — make friends in far-off places and be sure you are prepared when you need help.
2. They Ruthlessly Prioritize
Identifying high-value work and staving off distractions is a cornerstone of good product development. This requires us to be realistic when making trade-off decisions. Fear should not be part of the decision-making (“If we don’t do this now, we might never do it!”). Hope should not be part of the decision-making (“This better work out!”). Small teams need to make smart decisions about where to focus, and then maintain that focus despite all the things that can throw them off the path. Measure twice, then cut, cut, and keep on cutting — use continuous prioritization throughout the development lifecycle to keep the team on track.
For an engineering (i.e. not product) -focused discussion of what this means, John Ousterhout has a great chapter (page 17) called “Decide What Matters” in the new version of his book, A Philosophy of Software Design.
3. They work as an Integrated Team
Big impacts need big ideas, and the best thinking comes from diverse teams. This means integrating a diverse set of roles into the development process and team rituals right from the early stage. This is whole-team, “customer in the room”-style thinking. People in roles like product management, design, SRE, customer support can regularly join your stand-up, your milestone demos, and/or your amigos meetings.
Any time you can embed someone from that “other” team into your daily development cycle, it makes collaboration strong and the inevitable product phase transitions much easier. Armed with fast feedback and diverse thinking, you can make sure that what you are building will actually make a difference.
4. They Build Quality In
This phrase, which dates back 50 years to the days of Lean in manufacturing, will never be a cliché. When we continuously deliver elements of a quality strategy throughout the delivery process, we ensure that our system will hold up across the various stages of the development lifecycle. For example, in the early stages, we need design partners to come on board and get a reasonable experience. We want valuable feedback, not “you lost my data again” or “your system is down again.” Overall, as with point 3, this will make your product phase transitions easier and builds a lot of confidence with the people that are funding your product.
5. They Put People First
Putting people first means creating an environment with trust, transparency and alignment. It means creating circumstances where people can bring their best selves to work every day, operating with psychological safety. It does not, however, mean coddling or treating each other like spoiled children. We work as a team, not as a family (Reed Hastings). In reality, we put people first when we hold each other accountable — that is part of our responsibility to each other and our path to success as a team. Align on a shared set of values, help people put those values first, and create a culture where we feel good about holding each other accountable to them.
6. They Show Their Value
To have an impact, you need to know what value you are creating and be able to show that value to others, so they know how to leverage what you are building. Small teams need to find big ways to show what they are doing and get people excited about it. This means having a clear, always up-to-date articulation of your system and it’s part in the greater whole.
You are building something that needs to integrate into other systems as part of a larger product story. Get to know those systems and that story really well, because what you are a part of is more important than what you part are building.
Take the time to understand your adjacencies and how they work — go read their docs, deep dive into their architecture, walk through their code. Generate your own mental model for how everything fits together, don’t rely on someone else to do that for you. Create your vision, articulate it in docs or slides, and take every opportunity to get feedback on your thinking. You can use that as a great way to build relationships (back to point #1). You may not sell anyone on it, but you might get a seat at the table.
Practicing values in the workplace is key to a healthy culture, but we tend to focus on those relating to communication, planning or practices. I like to also reflect on how our personal values translate into the workplace.
Gratitude means being thankful by showing appreciation. When we practice gratitude, we channel our thanks into action. This means reacting to the good things that happen in our lives, but it also means carrying that energy forward into new experiences.
How use this energy in the workplace? We can practice Grateful Leadership! There is probably already a book with that name already (yep, just checked, there is …) but this is not a summary. I just want to jot down a loose idea for an approach that I think we should try to use more often.
To me, practicing “grateful leadership” means,
… finding a reason to appreciate the people you work with, every single day. Step 1 for building a grateful culture? Be thankful. This means taking the time to reflet on the moments that made your work better.
… sharing your feelings with your team. Feelings are infectious, and leading by example is how we spread them. Share your joy freely. Share it openly, in public at meetings, and privately in 1:1s. People might need some getting used to this, because it’s not always natural in the workplace.
… building a culture of recognition. Encouraging people to speak up: when you see something awesome, say something awesome. This is one area where it helps to nudge people to join in, and can be accomplished by something as simply as “… did you let them know that?”
… being thankful when people give you the gift of their time. That means using their time respectfully/responsibly, not wasting it or treating it flippantly. Make it interesting, make it fun, be mindful.
… being generous with your own time. Show your appreciation to others by giving them the gift of your time. Schedule those one on ones. Follow up with people that have had an impact on your work. If someone asks for a meeting, don’t wait for them to book it – open your calendar and show them you care by booking it yourself.
… looking at difficult situations as challenges, not problems. With an attitude of gratitude, we spin hard problems into learning adventures.
… letting people in to what’s going on in your head. Be generous with sharing your what’s on your mind. Describe your mental models, impart your knowledge, offer your feelings. When you let people in, you give them
the gift of being able to help.
Why gratitude? I find it energizing and motivating. It helps me bring my best self to work every day. And that’s something I encourage in others, because a grateful culture makes for a great place to work.
The important thing about gratitude is that it is more than simply being or feeling thankful. We need to act. We need to express our gratitude – share it, show it, live it. And bringing that into the workplace is incredibly powerful.