
This Article was Originally Published in InfoQ on August 16th
What color do you think of when you hear the word “red”?
Ask 100 people, they will give you 100 different answers. Even with an anchor to help—a can of Coke, perhaps—there will be differences.
So begins The Interaction of Color by Josef Albers, where he uses various color studies to show the complexity of their interactions. He notes that even professional artists are surprised when presented with his examples, which indicates just how fickle the human mind is at interpreting color.

To train the eye, he has learners run experiments that demonstrate concepts like intensity, brightness, reversal, transparency, addition, subtraction, mixture, and so on. In doing these experiments, students work through various scenarios, manipulating color combinations to reveal their interactions.
It is interesting to note that Albers does not use pigment or paint for such experiments. Instead, he uses paper cut-outs. These provide the most reliable way to test scenarios repeatedly. The printed colors are fixed and indivisible.
Indivisible elements are critical for experimentation because they are irreducible. They create a high degree of reliability, which is needed to work with tests and compare results.
In software, we also engage heavily in experiments, and we also need indivisibles to work with. We call these “primitives,” and they come in two types—dynamic and semantic.
Primitives of Dynamics
Software is built from layer upon layer of abstractions. Machine language is abstracted using microcode primitives, microcode is presented as higher-level languages, and so on. At each level, simple elements are presented that abstract away the complexity of the operations underneath.
Modern software development primarily involves synthesizing a variety of external elements: open source software, third party services, infrastructure APIs, and so on. We bring these together using code to create our systems. It is a world of composability, and our systems are mixtures of modules glued together with code.
Ideally, we would like to have elements that are designed to be used as primitives. Read the literature going back 50+ years, and you find the same good architectural advice: practice modular design—create primitive building blocks by strictly separating implementation from interface. “Don’t mix the paint!”
This is the logic that drove the development of AWS—offer customers a collection of primitives so they can pick and choose their preferred way to engage with the services, not a single framework that forces you into a specific way of working, which includes everything and the kitchen sink.

Of course in practice, at scale, it’s not that easy. See Hyrum’s Law, which says, with a sufficient number of users, all observable behaviors will be depended on by somebody. In other words, there is no such thing as a private implementation. We want to pretend that everything underneath the interface can be hidden away, but it’s not really the case.
If only we could rely on our interfaces like the artist relies on the laws of chemistry and physics. But the things we build with are much less dependable. Accidents can happen many layers underneath our work that result in massive change all the way up the stack (see Spectre or Meltdown).
Implementations also need to change over time, as we learn about our systems, their users, and how the users use them. What we are implementing are ideas about how to do “something,” and these ideas can and should change over time. And here we come to our second type of primitive.
Primitives of Semantics
Every software system is a solution to a problem. But if we start with assumptions about the solution rather than clear statements of problems, we may never figure out the best use of time and resources to provide value to customers.
Even if we had a crystal ball and knew exactly how to solve our users’ problems, it would still not be enough. We also have to know how to get there—a map of the the increments of value to be delivered along the way. We need to find stepping stones to a final product, and each stone must align to something a customer wants.
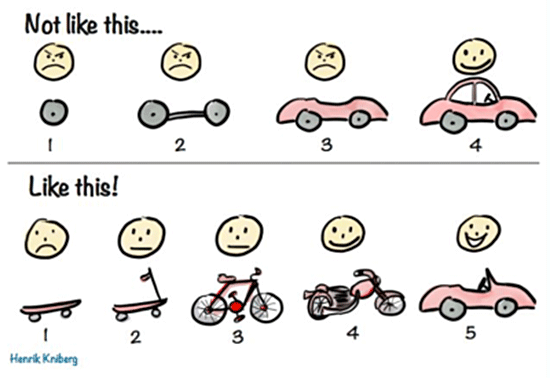
How do we do this? Again, we try to work from indivisible elements. I like to call these “semantic primitives.” We want these, our raw materials, to be discreet and independently evaluable. Again, “don’t mix the paint!”
These are implemented in various ways. The word “requirements” gets a lot of hate these days. “User stories” are popular, but “use cases” have fallen out of fashion. After a blog post on Medium, “jobs-to-be-done” became “the framework of customer needs” seemingly overnight.
Regardless of how you conceive them, the purpose is the same: to serve as building blocks for understanding the problem we want to solve and to help us be creative as we move along our product journey.
When starting with a set of semantic primitives, we can learn from one, make mistakes with another, fall over a third, pivot between the rest, and so on. In theory, they allow the development process to become changeable and continuously aligned to delivering incremental value to customers.
But again, in practice, they are challenging to work with. These are not exhaustive proofs or laws of mechanics. They are assumptions and estimations, usually based on poorly sampled probabilities and questionable causality, crafted loosely with a lot of grey language. And they have to be, because our understanding of our customers and their problems is necessarily incomplete.
Synthetic Systems
Let’s go back to the difference between “red” on paper and “red” in your mind. On paper, the color is stable, it is factual and replicable. But in your mind, the color is unstable and ambiguous. This is the world of objects vs. the world of our minds.
In software, we don’t have the luxury of primitives with stable dynamics like those found in the world of objects. Our systems are synthetic, made up of cognitive composites that are subject to change without notice. We work only inside the world of our minds.
The system dynamics we observe today may not be the same we observe tomorrow. The semantics that we wrote down today may no longer be valid tomorrow. We live in a world of constant uncertainty and emergent knowledge.
To work with such uncertainty, we need to adopt a corresponding mindset.
A big part of the journey in software is learning to suspend the heuristics and mental models that we rely on when interacting with the world of objects. Getting burned by misplaced trust or untested assumptions is part of the evolution from junior to senior.
So we learn to think differently, we learn to challenge everything we see. But is this enough?
It’s worse than we thought!
In his book, Thinking Fast and Slow, Daniel Kahneman talks at length about the ease with which we fool ourselves into believing in improbable outcomes, and how we are particularly susceptible to illusions of cognition.

Take the example of The Dress. After learning about this visual illusion we easily adjust our understanding. Once we know the truth, we correctly say that the color is black and blue, even though our eyes may still deceive us. We do this by consciously doubting what is presented.
But when it comes to illusions of cognition, it’s a different story. Evidence that invalidates ingrained thinking is not easily accepted. Look to the Dunning-Kruger effect, or even anti-vaxxers and flat-earthers for some extreme examples. This does not bode well for us.
Just like the professional artists that are surprised by Albers’ color studies, even the most grizzled veterans of software delivery will make surprisingly incorrect assumptions about their systems, about whether things will work, whether they will continue to work, whether they create value, whether they meet customer needs, and so on.
And it’s no wonder—living in a world of constant conscious doubt is hard. It demands a lot of energy. We have to be unrelenting to resist the urge of falling back on the heuristics we learned from the world of objects.
Conscious doubt creates cognitive strain, and doing so constantly is a heavy burden. This is probably one reason why software development has a high rate of “burnout.” So what do we do?
Systems of Synthetic Management
Let’s restate the problem:
- Our materials (code, interfaces, requirements, etc.) are derived from unstable primitives.
- To use our materials, we need to adopt a mindset of challenging everything.
- We can’t trust ourselves to consistently use that mindset.
The solution? Systems.
We can use systems that manage the uncertainty for us, that create bounded contexts of risk and bring new knowledge to the foreground as it emerges.
- We have the incredible power of programmability. We can invest heavily in the gifts given by the medium of code. We can construct elaborate systems of test automation, continuous integration, and production monitoring to unrelentingly test every one of the assumptions we make about how things are supposed to work.
- We have practices of agile, lean, and design-thinking to guide us in managing our semantics. We have developed methods driven by research and statistics to generate better primitives. We can work iteratively within boundaries that limit the scope of inevitable errors. We can use these practices to find metastable states that enable us to move forward.
We are still maturing these systems of synthetic management, developing the competencies required to manage and control our work’s synthetic nature. It pays to remember that it has been only 20 years since the discovery of Agile and even less since the word DevOps was coined. Our field is new, and we have not yet mastered these ways of working, though of course we easily slip into cognitive illusions that convince us otherwise.
All kinds of work involve overcoming illusions. But software has the added burden of resisting the siren’s song of a stable world of dynamic and semantic primitives. Fortunately, we can create systems to escape from it, and the development of those systems will define our success in delivering value with software.
